Research on deep learning and machine learning has been going on from the last 40 - 50 years. The first CNN was proposed by Yann Lecun in the early 90’s. Even going by the research suggested that it was very efficient model to identify and differentiate between various classes but the compututaional power required by the model was unavailable at that time.The computational power required to process the millions and billions of parameters of a neural network has been acquired in the last 10 years only since the arrival of highly efficient GPUs. And thus, began the explosion of deep learning and machine learning in actual practical sense apart from the theoretical research.
This post is the first in the series that I would be publishing as I go through some of the classical and popular papers that laid to the foundation of modern deep learning research. These are also my personal understanding of the paper which could have some flaw, so please do feel free to correct me.
Although current state of art have progressed way past the benchmarks in these papers but it’s good to look through the past in order to get a deeper understanding as to why and how these papers succeeded. Later on maybe, I will also go through some of the recent papers as I play the catch-up game here.
AlexNet and ImageNet
The ImageNet competition is a world wide open competition where people, teams and organizations from all over the world participate to classify around 1.5 million images in over 1000 classes. These classes are dogs, cats, birds, person, trees and many other categories and their subcategories. This is an annually held competition where people compete to get their model to the best possible accuracy for classifying all the classes.
In 2011, Alex Krizhevsky, Ilya Sutskever and Geoffrey E. Hinton took over the winner position with a Deep Convolutional Neural Network that they had trained on the 2010 ImageNet data. Earlier to this day, no one had attempted of using CNN for this competition. They achieved top-1 and top-5 error rates of 39.7 % and 18.9 % which was considerably better than the previous state-of-the-art results.
Architecture of AlexNet
AlexNet has a 8 layered architecture which comprise of 5 convolutional layers, some of which have max-pooling layers following the convolutional layers and 3 fully- connected layers or dense layers. They used a newly developed regularization technique (in that time) which now we know as Dropout.
There are five convolutional layers followed by three dense or fully-connected layers. The output of the last layer is fed to a 1000 way softmax classifier which classifies a given image over the 1000 class labels. The first, second and fifth convolutional layers are followed by max-pooling layers. Along with this, activation function Rectified Linear Units or ReLU is added to each layer. Each dense layer is followed by Dropout layer having 0.5 probability.
The original network was trained on two GPUs due to the memory constraint. The first convolutional layer receives input image of the dimensions 224 X 224 X 3. It consists of 96 filters/kernels with size 11 X 11 X 3 having strides of size 4 pixels. The second convolutional layer receives the noramlized and maxpooled output from the first layer. The second layer consists of 256 filters having kernel size of 5 X 5 and stride of 1 pixel. Each maxpooling layer has pooling size of 3 X 3 having stride of 2 pixels. It is to be noted here that only first two convolutional layers have normalized inputs, the rest of the layers do not have any normalization.
The third and fourth layers have 384 filters with 3 X 3 kernel size and 1 pixel stride. The fifth layer has 256 filters with kernel size of 5 X 5 and stride of 1 pixel. The third, fourth and fifth convolutional layers have maxpooling layers as described above.
The output from the above layers are fed to the fully-connected layers. The first two fully-connected layers have 4096 neurons each. The last layer has 1000 neurons over a softmax classifier.
The original architecture from the paper is as follows -
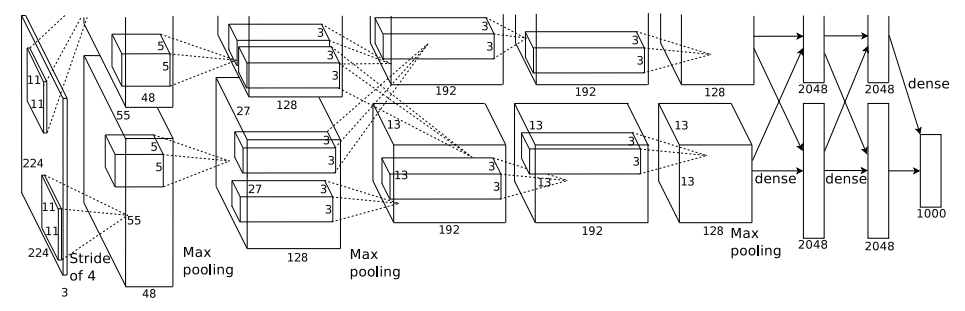
It was spread across two GPUs in order to fit the neural net in memory. The network was trained on GTX 580 GPU having only 3GB of memory. Hence, the authors used cross GPU parallelisation over two GPUs to train the network on the ImageNet data.
Here is the same architecture I implemented using Keras running on a single GPU. In this architecture, I have merged all the layers which were distributed over two GPUs. This model is trained and validated on the CIFAR-10 dataset.
Tackling Overfitting
When a model performs well on training set but given an unseen dataset, it cannot generalize to it, this is known as overfitting. The model will give a great accuracy on the training set but on the test set, it fails to perform on par as it has modelled the training data too well.
Given the big CNN that the authors were using to train the data, it began to overfit. In order to reduce the authors employed two techniques - data augmentation and using dropout. Data augmentation is the artificial generation of data for enlarging the dataset. This is done by translating, rotating through the two axes, flipping the original images, etc. This results in generation of more images which can be used to train the model in order to reduce overfitting.
Another method used was introduction of dropout after each of the fully-connected layers. Dropout, in simple words can be understood as randomly ignoring (“dropping”) some neurons during training phase. By “dropping” or “ignoring”, we mean that these neurons are not considered for a particular forward or backward pass. At each stage, the neurons are either kept with probability ‘p’ or removed with probability of ‘1 - p’. Dropout forces the network to learn more robust features and hence, takes roughly double the time to converge.
Dropout can be easily modelled in keras as follows -
from keras.layers import Dropout
Dropout(rate, noise_shape=None, seed=None)
Impressive Results
The CNN model produced ground-breaking results in the 2012 ImageNet competition. The network achieved top-1 and top-5 test set error rates of 37.5 % and 17.0 % respectively on the 2010 dataset. The best performance achieved during the 2010 competition was 47.1 % and 28.2 %. In the 2012 version, this neural net achieves a top-5 error rate of 18.2 %. AlexNet significantly outperformed all the prior competitors and won the challenge by reducing the top-5 error from 26% to 15.3%. The second place top-5 error rate, which was not a CNN variation, was around 26.2%.